Sometimes data comes in a nicely packaged format like a csv or a database table… and sometimes it doesn’t. So what do you do when you need to grab some data from a website, but there is no API available? Scrape It!
I’m an avid MMA fan and from time to time I want to check out some data on fighters. Sherdog.com provides data on fighters including:
- Win/Loss Record
- Camp
- Weigth/Height
- Specifics about each fight: opponent, result, referee, event, etc.
However Sherdog doesn’t have an API; this is where beautiful soup comes in. I ran a quick google search for Sherdog web scrapers and found one by Andrew Valish which was written in Node.js. I used this as a template and resource for the examples I provide below. NOTE: In case you are looking for a prebuilt solution using Python, there are a couple of Python based Sherdog scapers available on Github. (Please see References section for links)
Conor McGregor is fighting for the UFC Featherweight title at UFC 194 on December 12th against the reigning champ Jose Aldo. So let’s take a look at some of his stats. The first step is to import beautiful soup and then read the web page.
from bs4 import BeautifulSoup
import urllib
import re
r = urllib.urlopen('http://www.sherdog.com/fighter/Conor-McGregor-29688').read()
soup = BeautifulSoup(r)The initial contents of soup are shown below (using the soup.prettify() function)
<!DOCTYPE html>
<html version="XHTML+RDFa 1.0">
<head>
<title>
Conor "Notorious" McGregor MMA Stats, Pictures, News, Videos, Biography - Sherdog.com
</title>
<meta charset="utf-8"/>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="en-US" http-equiv="Content-Language"/>
<meta content="Sherdog.com" name="author"/>
<meta content="Sherdog.com" name="publisher"/>
<meta content="2015 - Sherdog.com" name="copyright"/>
<meta content="INDEX, FOLLOW" name="robots"/>Ok, so that doesn’t look very useful, but there are a variety of tools to help us sort out what pieces of data we want. The gif below shows how to view developer tools in Chrome. You can see as I move the cursor over the HTML elements they are highlighted in the page.
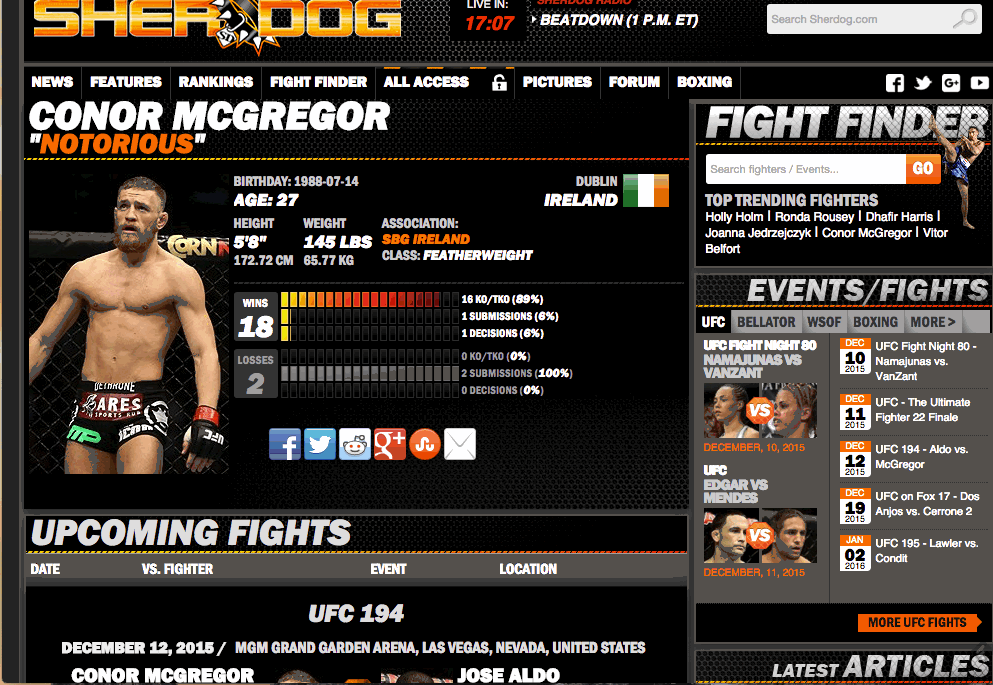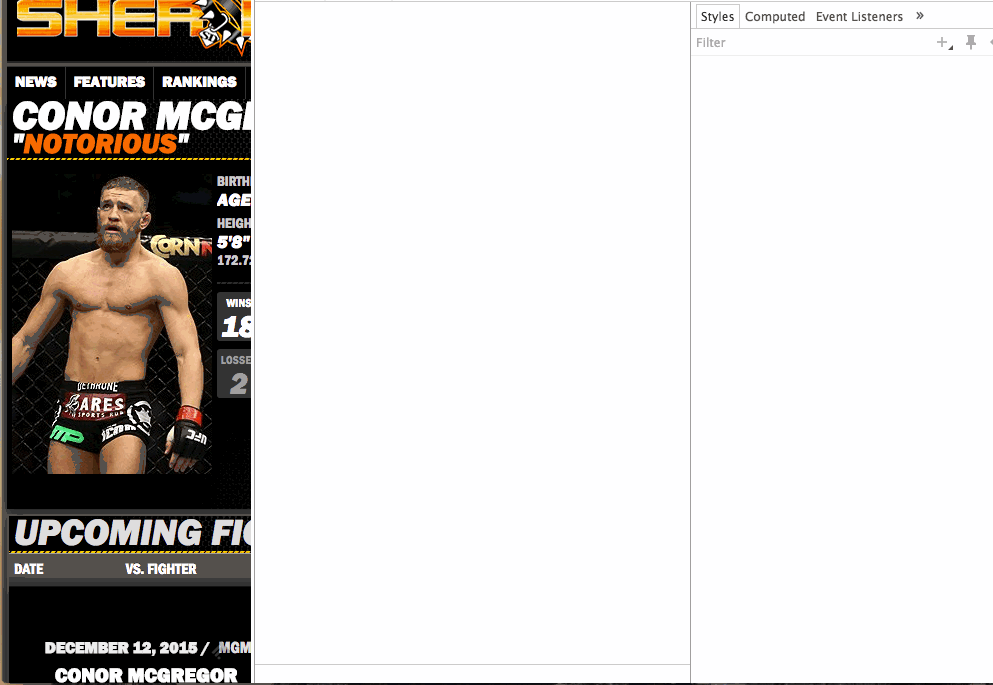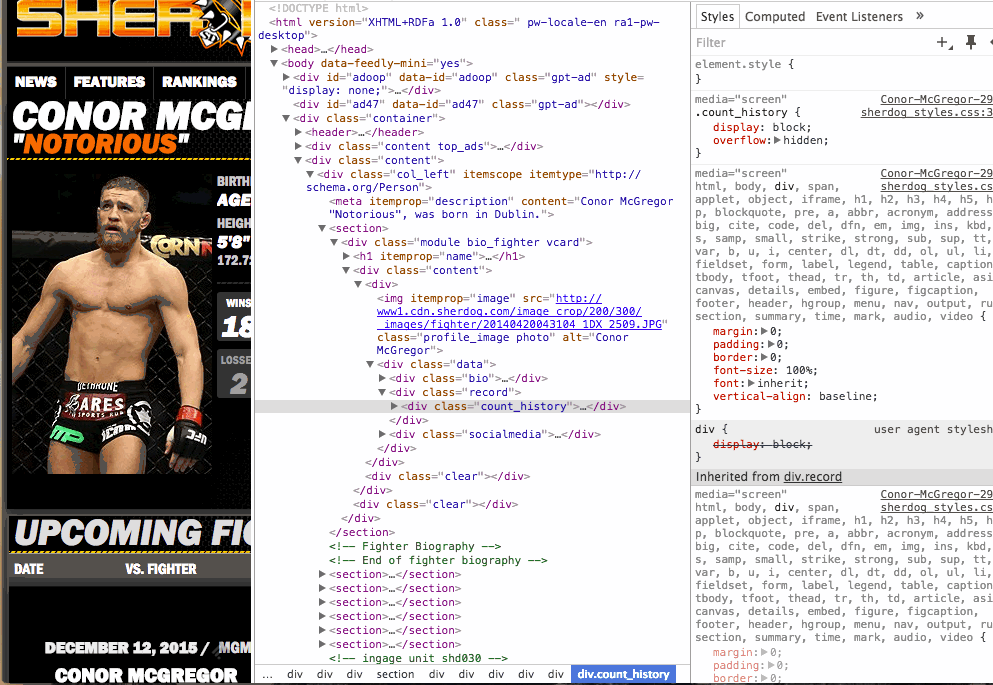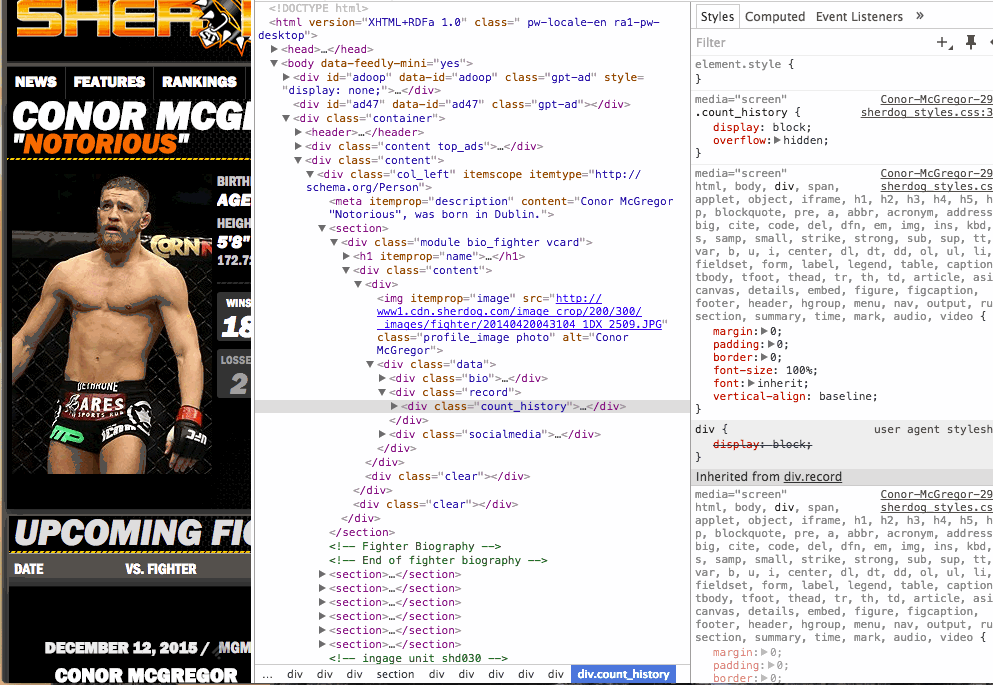
I’ll start with collecting the fighter name and nickname:
fighterName = soup.find('span', class_ = 'fn').get_text()
nickname = soup.find('span', class_ = 'nickname').get_text()I reference the name and nickname using the css class in the html. I search soup for the fighter name via the find function using both the html element, span, and the css class name, fn. The section of HTML containing this text is shown below:
<span class="fn">
Conor McGregor
</span>
<br/>
<span class="nickname">
"
<em>
Notorious
</em>
"
</span>Similarly, I collect Conor’s birthday, weight, height, nationality, and association (team):
birthday = soup.find(itemprop = 'birthDate').get_text()
age = soup.find('span', class_ = 'item birthday').find('strong').get_text()
locality = soup.find(itemprop = "addressLocality").get_text()
nationality = soup.find(itemprop = "nationality").get_text()
association = soup.find(class_ = 'item association').find('span', itemprop = 'name').get_text()
height = soup.find(class_ = 'item height').find('strong').get_text()
weight = soup.find(class_ = 'item weight').find('strong').get_text()
weightClass = soup.find(class_ = 'item wclass').find('strong').get_text()In this case I will identify the birth date by searching on the itemprop field birthDate. To isolate the fighter’s age I access the strong tag located in the item birthday class.
<div class="data">
<div class="bio">
<div class="birth_info">
<span class="item birthday">
Birthday:
<span itemprop="birthDate">
1988-07-14
</span>
<br/>
<strong>
AGE: 27
</strong>
</span>Sherdog also provides information about each of a fighter’s fights in a table. We can scrape this data as shown below:
fight_history_table = soup.find(string = 'Fight History').find_parent(class_ = 'module fight_history').find('table')The table is inside of a div of class module fight_history, but there is also another table which displays the amateur record of the fighter in a similar div. To identify the table with the professional record, I need to first identify the location of the text string Fight History which is the header for the table we want. Conversely the amateur record is labeled with the string Amateur Fights. Once the string is identified I locate the parent tag with a class of module fight_history and then search for a table element. To clarify, when using the find function you are searching down the html tree, but when using find_parent you are working your way up the tree. Below are snippets showing the similarity of the amateur and professional tables.
<div class="module fight_history">
<div class="module_header">
<h2>
Amateur Fights
</h2>
</div>
<div class="content table"> <div class="module fight_history">
<div class="module_header">
<h2>
Fight History
</h2>
</div>
<div class="content table">Next we want to go row by row and collect the information about each fight. The code below outlines how to do this. The rows of the table are identified by the css classes odd and even. For each row we isolate the desired data. For more information on iterating through tables check out this Stack Overflow post.
rows = fight_history_table.find_all(class_ = {'odd','even'})
for row in rows:
cells = row.find_all("td")
result = cells[0].get_text()
opponent = cells[1].get_text()
event_name = cells[2].find('a').get_text()
event_url = cells[2].find('a').get('href')
event_date = cells[2].find(class_ = 'sub_line').get_text()
method = cells[3].get_text()
referee = re.split('\)', method)[1]
method = re.sub(referee, "", method)
rd = cells[4].get_text()
time = cells[5].get_text()The first couple of results are shown below:
print result + " : " + opponent + " : " + event_name + " : " + \
event_url + " : " + event_date + " : " + method + " : " + \
referee + " : " + rd + " : " + time + "\n\n"
win : Chad Mendes : UFC 189 - Mendes vs. McGregor : /events/UFC-189-Mendes-vs-McGregor-42211 : Jul / 11 / 2015 : TKO (Punches) : Herb Dean : 2 : 4:57
win : Dennis Siver : UFC Fight Night 59 - McGregor vs. Siver : /events/UFC-Fight-Night-59-McGregor-vs-Siver-41773 : Jan / 18 / 2015 : TKO (Punches) : Herb Dean : 2 : 1:54As I pointed out earlier, this was just an example to help highlight what can be done with beautiful soup. Check out the sources below for prebuilt solutions in both Python and Node.js (specifically for scraping Sherdog)