I recently had the oppurtunity to do a lightning talk at the first annual Data Jawn event hosted by RJ Metrics. Myself and Lauren Ancona presented a small project we had been working on known as Twimoji. We collected tweets geolocated in the Philadelphia area for a couple of months and decided to look at emoji use in tweets.
My first contribution to the project was to isolate the emojis in each tweet and determine the number of tweets which used each emoji. The tweets were collected using IFTTT and saved in a series of csv files. The tweet files are imported followed by a copy of Tim Whitlock’s Emoji Unicode Tables labeled as emoticon_conversion_noGraphic.csv in the code below.
library(readxl)
library(dplyr)
library(RWeka)
# get list of files
fin <- list.files(path = "data/", full.names = T)
# import and combine files
ds.list <- lapply(fin, read_excel, col_names = F)
ds <- unique(do.call(rbind.data.frame, ds.list))
# read in emoji tables and assign names to cols
emoticons <- read.csv("emoticon_conversion_noGraphic.csv", header = F)
names(emoticons) <- c("unicode", "bytes","description")
names(ds) <- c("created","screenName", "text" , "ID", "map.info.A", "map.info.B")After importing the data I used the RWeka package to tokenize the tweets. The next step is to identify which emoji are present in each tweet. Below you will see a simple for loop coupled with a regular expression statement to search for each emoji in the table.
# get word frequencies and tokens
tokens <- WordTokenizer(ds$text)
emoji.frequency <- matrix(NA, nrow = nrow(ds), ncol = nrow(emoticons))
for(i in 1:nrow(emoticons)){
emoji.frequency[,i] <- regexpr(emoticons$bytes[i],ds$text, useBytes = T )
}As an R user I am well aware of the cons of using a for loop and therefore I will offer up a more efficient way to identify the emoji. I use vapply to accomplish the same task below. To confirm the results are identical I use the all.equal function to compare the results.
emoji.frequency.vapply <- vapply(emoticons$bytes,
regexpr,FUN.VALUE = integer(nrow(ds)),
ds$text, useBytes = T )
> all.equal(emoji.frequency, emoji.frequency.vapply)
[1] TRUEEach column in the emoji.frequency matrix represents an emoji in the table. If the emoji is not present in a tweet the value is -1, otherwise the value returned by the regexpr function is the position of the emoji in the tweet. To calculate the number of tweets which contain each emoji the colSums function is utilized. The frequency of each emoji in the data set is appended to the original emoticons data.frame.
emoji.counts <- colSums(emoji.frequency>-1)
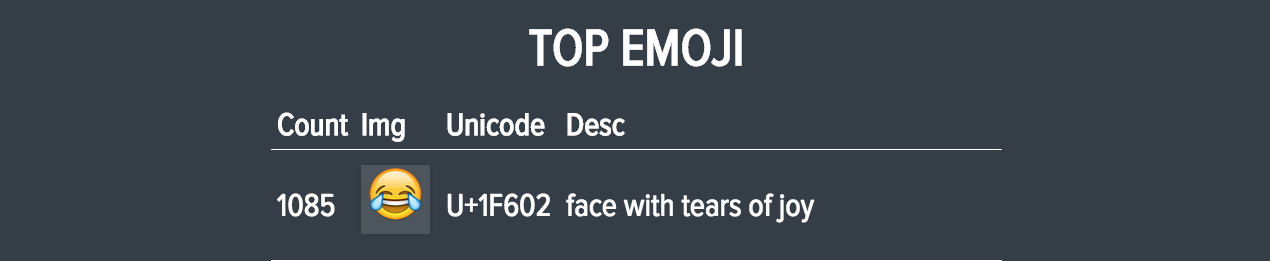
emoticons <- cbind(emoji.counts, emoticons)We found the most frequently used emoji were:
Although the focus of this post was identifying the frequency of emoji use in tweets, I figured I’d end with some great visualizations of the data we collected. Lauren made some amazing maps showing all the tweet locations over time:
As well as a heat map showing tweet density over time for tweets containing emoji:
Please feel free to check out the slides from our presentation as well as the git repo containing the project.