4 Word Representations
This chapter offers a general overview of how documents and words are viewed and processed during topic modeling.
4.1 Bag of Words
LDA processes documents as a ‘bag of words’. Bag of words means you view the frequency of the words in a document with no regard for the order the words appeared in.
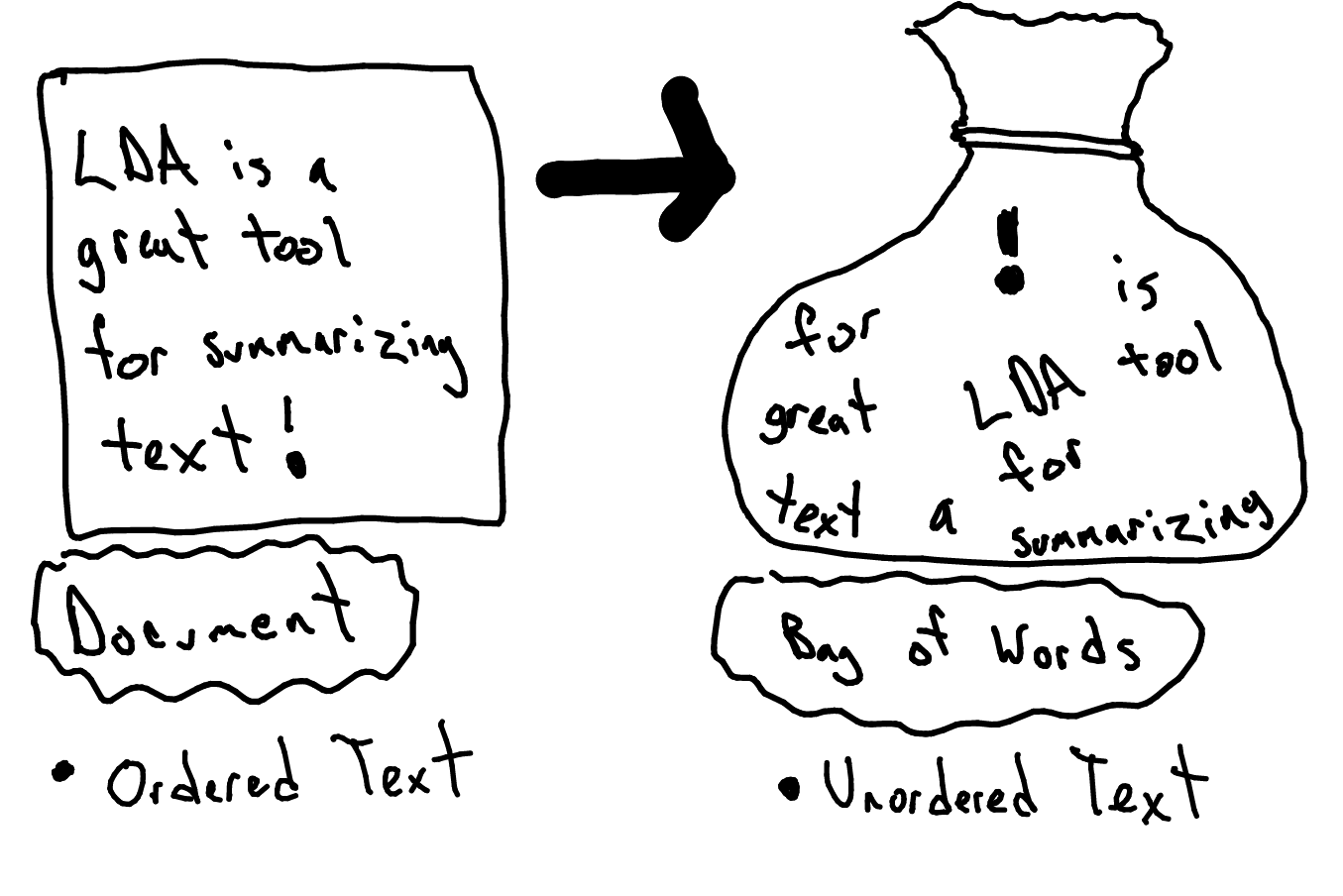
Figure 4.1: Bag of Words Representation
Obviously there is going to be some information lost in this process, but our goal with topic modeling is to be able to view the ‘big picture’ from a large number of documents. Alternate way of thinking about it: I have a vocabulary of 100k words used across 1 million documents, then I use LDA to look 500 topics. I just narrowed down my feature space from 100k features to 500 features (dimensionality reduction).
Possible examples: Scrabble in reverse
4.2 Word Counts
For the purposes of LDA we need a way of summarizing our documents. We need to keep count of the following:
- Topic Term Matrix (variable name: n_topic_term_count, dimensions: Topic x Vocabulary): In the case of LDA, a single unique word can be assigned a different topic for each instance of the word (or generated from more than 1 topic in the case of a generative model.)
- Document Topic Matrix (variable name: n_doc_topic_count, dimensions: Document x Topics): This is the total number of words assigned to each topic in each document.
- Topic sum vector (variable name: n_topic_sum, dimensions: 1 x Topics): The topic sum vector keeps count of the total number of words in the entire corpus (all docs together) assigned to each topic. This is just a column sum of the document topic matrix.
The structures above are necessary for performing inference tasks utilizing LDA. We will go over how these structures are initialized, updated, and utilized in Chapter 6.
4.3 Plug and Play LDA
Considering most people are not going to be writing LDA code from scratch, it is worth mentioning that when using most software packages for LDA the only structure you will need to build is a term-document matrix. This is a matrix that has a single row for each term in the vocabulary and a single column for each document. This is a common input across packages such as Gensim (Python), Scikit-learn (Python), and TopicModels (R) (some are doc-term, some are term doc, so double check the package docs). Mallet uses something similar, but the user only needs to make a document file. Nearly all of the packages mentioned also have additional helper functions to convert lists of documents to the required input format.